
.svg)
.svg)

Este artigo tem como objetivo detalhar o desenvolvimento de testes e comparações entre diferentes soluções de Guardrails. O estudo foi conduzido para comparar o uso do framework Guardrails AI com soluções que utilizam apenas técnicas de prompt. Além disso, visa avaliar como a escolha do LLM, seja GPT ou open-source, e a temperatura aplicada ao modelo influenciam o desempenho das soluções.
Para auxiliar no desenvolvimento e ter uma situação aplicável de uso, optamos pelo cenário de Agentes Conversacionais. Essa escolha se justifica pela relevância atual dessas tecnologias em diversos setores, como atendimento ao cliente, suporte técnico e assistentes virtuais.
Os agentes conversacionais representam um ambiente ideal para testar diferentes estratégias de guardrails devido à complexidade de suas interações e à necessidade de garantir respostas apropriadas, éticas e precisas. Ao lidar com uma variedade de inputs de usuários, esses sistemas enfrentam desafios significativos, como compreensão de contexto, prevenção de respostas inadequadas e gerenciamento de variações linguísticas.
Para a preparação da base de dados, desenvolvemos um conjunto de 36 perguntas e respostas especificamente no contexto de seguros e cobrança. A construção dessa base foi realizada manualmente, com um processo criterioso de seleção que incluiu a criação de perguntas que simulassem diferentes cenários: mensagens não seguras, mensagens seguras e perguntas fora do contexto original. Essa abordagem metodológica permitiu criar um conjunto de dados representativo e capaz de testar de forma abrangente os diferentes mecanismos de guardrails.
Foram desenvolvidas duas abordagens distintas de guardrails para o benchmarking: a primeira utilizando o framework Guardrails AI, uma solução especializada em implementação de barreiras de segurança, e a segunda empregando um modelo de linguagem de grande escala (LLM) combinado com técnicas avançadas de engenharia de prompt, com o objetivo específico de limitar e controlar as respostas do modelo.
Na solução com Guardrails AI, a implementação foi estruturada utilizando a BaseModel do Pydantic, seguindo práticas observadas em implementações prévias do framework. O objeto "guard" desempenha um papel central, responsável por compor o prompt completo, integrando elementos como a completude do LiteLLM, a classe de estruturação da saída, o prompt de sistema, a mensagem do usuário e o histórico de conversas. O framework realiza internamente a estruturação do prompt de forma automatizada.
Já a segunda solução desenvolvida se baseia exclusivamente em técnicas de engenharia de prompt, sem utilizar um framework dedicado de guardrails, o que permite uma comparação direta entre as diferentes abordagens de implementação de barreiras de segurança para modelos de linguagem. Ambas as implementações foram desenvolvidas com classes que facilitam a alteração do modelo e da temperatura utilizada.
Para automatizar os testes, foi desenvolvida uma classe que facilita a execução e a avaliação das duas soluções propostas. Essa classe é responsável por gerir o processo de testes e possibilitar que eles sejam realizados de forma mais dinâmica.
Inicialmente, a base de dados de teste é carregada a partir de um arquivo JSON, e esse conjunto é armazenado em uma variável. A classe contém loops que percorrem cada combinação de modelo e temperatura definida para cada um dos itens da base de dados, passando essas informações para as duas soluções.
Para os testes, foram utilizados os modelos phi35-vision-instruct e gpt-4o, com temperaturas variando entre [0, 0.1, 0.2, 0.3, 0.4, 0.7, 1]. O tempo de execução de cada teste é calculado utilizando a biblioteca time do Python, permitindo uma análise do desempenho e da eficiência de cada solução.
Para cada um dos guardrails, são armazenadas a classificação retornada, o tempo da chamada do modelo, o índice da pergunta, a temperatura e o modelo utilizado para cada item da base. Após a finalização dos loops, esses resultados são salvos em um outro arquivo JSON, que posteriormente será utilizado para criar as tabelas de resultados.
Para a geração das tabelas de resultados, foi desenvolvido um script que processa os dados dos testes armazenados nos arquivos JSON. O objetivo é criar tabelas que facilitem a visualização e análise do desempenho das soluções para diferentes temperaturas.
Primeiramente, os dados de resultados são carregados a partir de um arquivo JSON e armazenados em uma estrutura organizada por temperatura. Isso permite que resultados específicos de cada configuração de temperatura sejam salvos em tabelas separadas.
Para gerar as tabelas, os dados são convertidos em um DataFrame do Pandas e salvos como um arquivo Excel. Além disso, uma tabela visual é gerada e salva como imagem utilizando o Matplotlib, proporcionando uma maneira rápida de visualizar os resultados.
Durante o processo de geração da tabela, a classificação de cada item do JSON de resultados é comparada com a classificação da base de dados. Com isso, é criada uma coluna adicional que indica "true" se o resultado for coerente e "false" caso contrário.
Os gráficos gerados foram de porcentagem de acertos, tempo médio e quantidade de acertos e erros para cada configuração e um tabela com as métricas gerais.



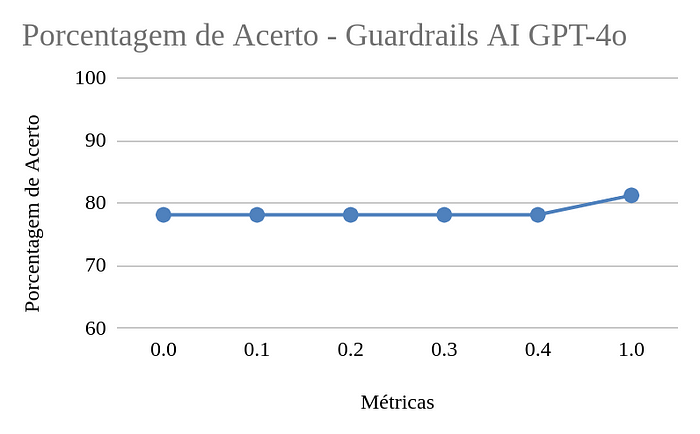










A análise dos resultados revelou que a implementação do Guardrails AI, utilizando o modelo do Pydantic, não ofereceu vantagens sobre a solução baseada apenas em prompt. Na verdade, o desempenho foi inferior tanto na precisão quanto no tempo médio de resposta do modelo. O estudo mostrou que, na implementação atual, o JSON para limitar o contexto utiliza apenas técnicas de prompt adicionando um texto a mais na montagem do prompt.
Embora existam outras funcionalidades que possam ser exploradas no framework que podem melhorar esse desempenho, dentro do nosso contexto de uso de guardrails, consideramos mais vantajoso desenvolvermos soluções próprias para cada caso. Isso porque é difícil encontrar uma solução única que abranja todas as necessidades e mantenha um bom desempenho.
Além disso, o framework tem limitações no suporte a modelos, acessando apenas modelos open source por meio do LiteLLM, e possui pouca documentação disponível, o que pode ser um fator limitante em situações futuras.
Os resultados indicaram que o GPT-4o tem um desempenho significativamente superior ao phi35 quando comparamos a porcentagem de acertos em ambas as soluções. Embora a diferença nos tempos médios de resposta não tenha sido tão grande, o GPT-4o apresentou respostas mais rápidas na maior parte dos casos.
Ao analisar as questões incorretas, nota-se que os erros do phi35 são mais preocupantes, enquanto o GPT-4o teve dificuldades apenas em situações mais ambíguas. Além disso, utilizando o GPT com o Guardrails AI, alguns prompt injections foram efetivamente barrados pelo content_filter interno, o que não ocorreu com o phi35 ou nem na solução baseada apenas em prompt. Isso pode estar relacionado a algum parâmetro interno do framework.
Outro ponto negativo do phi35 foi a ocorrência de várias falhas durante os testes com Guardrails AI, onde ele não retornou nenhuma classificação,não sabe-se o motivo ao certo, já que essa falha não ocorreu na solução baseada apenas em prompt, pode ser um problema com a versão ou servidor do modelo que foi utilizado.
Por fim, o GPT conseguiu manter exatamente os mesmos resultados com a mudança de temperatura. Como próximo passo, pode ser interessante testar o desempenho com outros modelos open source.
Ficou claro que o guardrails realmente trabalha melhor utilizando temperaturas menores no contexto geral. Porém com a utilização do GPT o desempenho não se alterou muito quando mudou a temperatura. Em alguns casos o desempenho foi até maior com a temperatura sendo 1, mas isso não é algo recomendável e seguro.
Somos uma startup inovadora com duas áreas de negócios: SaaS e AIaaS. No SaaS, oferecemos soluções avançadas para a hyperautomação de atendimento, facilitando a gestão, automação e acompanhamento de solicitações. No AIaaS, nossa plataforma Tech4.ai capacita empresas a construir e implementar soluções de inteligência artificial com tecnologias open source, garantindo agilidade, governança e alto desempenho.
E acesse, em primeira mão, nossos principais conteúdos diretamente do seu e-mail.
