
.svg)
.svg)
.png)
OCR, ou Reconhecimento Óptico de Caracteres (do inglês Optical Character Recognition), é uma tecnologia que permite a conversão de diferentes tipos de documentos, como PDFs, imagens digitalizadas e fotos, em texto editável e pesquisável.
Diante disso, este artigo consiste em um estudo teórico sobre extração de dados de documentos com OCR, comparando diferentes soluções de OCR e modelos de Vision AI. Ele surgiu da necessidade de aprimorar os sistemas de extração de dados de documentos, com o objetivo de reduzir a latência e aumentar a precisão no processamento. Para isso, a análise avaliou alternativas que equilibrassem velocidade e qualidade na extração de informações.
Em um cenário onde eficiência e precisão na extração automatizada de dados são cruciais, compreender as capacidades e limitações dessas tecnologias torna-se essencial. Por essa razão, esse benchmark também não se limitou a comparar o desempenho técnico das soluções, mas também buscou identificar abordagens que garantissem resultados mais consistentes e confiáveis no processamento de documentos diversos.
Os OCRs modernos, no geral, seguem algumas etapas de funcionamento, são elas:

O processo de identificação de caracteres varia conforme o tipo do material analisado, já que formatos padronizados e layouts variados apresentam desafios diferentes. Para lidar com essas demandas, destacam-se duas principais técnicas de OCR para extração de dados de documentos:
Essa metodologia compara caracteres capturados com exemplos pré-definidos. Cada caractere identificado é confrontado com um banco de dados de padrões conhecidos, permitindo que o sistema determine com precisão o caractere mais semelhante. Essa estratégia é ideal para materiais com fontes padronizadas, pois garante maior eficiência.
A Análise de Características foca nas particularidades de cada caractere, como linhas, curvas e traços. Isso é especialmente eficaz para lidar com estilos variados de escrita, incluindo manuscritos, oferecendo flexibilidade e alta precisão em contextos mais complexos.
O tesseract é uma das abordagens mais conhecidas de OCR. Desenvolvido pela HP em 1980, ele é atualmente uma solução open-source disponibilizada pelo Google. Inicialmente, o tesseract não utilizava modelos de deep learning, somente utilizava princípios tradicionais de processamento de imagem, que envolvem lógicas manuais e heurísticas.
No entanto, a partir da versão 4.0, ele incorporou um modelo LSTM (Long Short-Term Memory), que é um tipo de rede neural recorrente. Essa mudança aumentou significativamente a precisão no reconhecimento de textos, já que as LSTMs são altamente eficazes na aprendizagem de sequências e no entendimento do contexto dos caracteres dentro de uma linguagem.

Baseado em TensorFlow 2 e PyTorch, essa solução é muito útil para extrair dados de documentos e imagens. Além de contar com modelos pré-treinados para detecção e reconhecimento, ela também permite a criação de modelos customizados, ajustados às necessidades específicas de cada aplicação ou conjunto de dados. Para isso, oferece diferentes arquiteturas voltadas tanto para a detecção quanto para o reconhecimento de texto.
Se quiser testar rapidamente essa tecnologia, acesse: Doctr no Hugging Face.
O Text Detection identifica elementos textuais em imagens, reconhecendo caracteres em sequência contínua, ou seja, palavras. Esses elementos podem ser localizados de diferentes formas, como caixas delimitadoras, polígonos ou segmentação binária, que define se um pixel pertence ou não ao texto. A tecnologia também é capaz de lidar com documentos rotacionados e distorcidos.
Para essa tarefa, o docTR oferece diversas arquiteturas de detecção, incluindo:
linknet_resnet18, linknet_resnet34, linknet_resnet50db_resnet50, db_mobilenet_v3_largefast_tiny, fast_small, fast_baseSendo que cada arquitetura se baseia em um modelo específico para otimizar a detecção de texto:
Para uma comparação detalhada dessas arquiteturas no PyTorch e TensorFlow, acesse a tabela de comparação.
O Text Recognition tem como objetivo transcrever a sequência de caracteres presentes em uma imagem, convertendo-os em texto editável. Para isso, o docTR oferece diferentes arquiteturas de reconhecimento, cada uma com características específicas.
As arquiteturas disponíveis incluem:
crnn_vgg16_bn, crnn_mobilenet_v3_small, crnn_mobilenet_v3_largesar_resnet31mastervitstr_small, vitstr_baseparseqCada uma dessas arquiteturas se baseia em um modelo específico para otimizar o reconhecimento de texto:
Para uma comparação detalhada dessas arquiteturas no PyTorch e TensorFlow, acesse a tabela de comparação.
O docTR oferece diversos parâmetros configuráveis para aprimorar o reconhecimento de texto. Entre os principais estão:
straighten_pages: Ajusta a orientação da página antes do processamento, permitindo a extração de texto em documentos na horizontal e na vertical.assume_straight_pages: Se ativado, ajusta as caixas delimitadoras para documentos que já estão retos.preserve_aspect_ratio: Mantém a proporção dos documentos ao redimensioná-los antes do processamento.symmetric_pad: Garante que o preenchimento seja aplicado de forma simétrica, em vez de apenas no canto inferior direito.export_as_straight_boxes: Permite exportar caixas delimitadoras retas mesmo em documentos inclinados ou girados.resolve_lines: Agrupa palavras automaticamente em linhas (padrão: True).resolve_blocks: Agrupa automaticamente as linhas em blocos de texto (padrão: False).paragraph_break: Define o espaço mínimo entre parágrafos (padrão: 0,035).disable_page_orientation e disable_crop_orientation: Desativam a orientação automática da página e do recorte, respectivamente.O docTR está disponível sob a licença Apache-2.0, permitindo seu uso e modificação em diversos projetos.
EasyOCR é uma biblioteca de OCR em Python baseada em PyTorch, projetada para ser simples e flexível. Suporta cerca de 80 idiomas, incluindo o português, e permite o uso e treinamento de modelos personalizados para detecção e reconhecimento de texto.

O EasyOCR segue um fluxo estruturado para converter imagens em texto, utilizando PyTorch como base para seus modelos de aprendizado profundo.
EasyOCR está disponível sob a licença Apache-2.0, permitindo uso e modificação livremente.
O Keras-OCR é uma biblioteca de OCR baseada em deep learning criada com base no Keras e no Tensor Flow. Esta é uma versão ligeiramente polida e empacotada da implementação do Keras CRNN e do modelo de detecção de texto CRAFT publicado. Além disso, ele fornece uma API de alto nível para treinar um pipeline de detecção de texto e OCR.
O PaddleOCR é baseado no PaddlePaddle, uma plataforma de aprendizado profundo. Ele é projetado para ser altamente eficiente e flexível, suportando desde a detecção de texto em imagens até o reconhecimento e recuperação de informações textuais.

Vision Language Models são modelos capazes de aprender simultaneamente a partir de imagens e textos, permitindo que realizem diversas tarefas, como responder perguntas visuais e gerar legendas para imagens. Eles combinam técnicas de visão computacional e processamento de linguagem natural para entender e gerar conteúdo que envolve ambos os tipos de dados.
Para garantir um padrão nos testes, os arquivos .pdf foram convertidos para .png, permitindo que os modelos trabalhassem exclusivamente com imagens. A experimentação começou pelos modelos de visão, considerando possíveis mudanças futuras na API.
Para facilitar a execução dos testes, foi desenvolvida uma classe base que permite chamadas via LiteLLM e formata automaticamente o prompt de imagem. Além disso, uma estrutura foi criada para processar todos os documentos e salvar os resultados em uma tabela, garantindo maior organização e comparabilidade dos dados extraídos.
Os testes foram realizados com os modelos GPT-4o, GPT-4o-Mini, Gemini-1.5-Flash-001 e Gemini-1.5-Flash-002. Para cada um, foram fornecidos os campos do schema do documento, acompanhados de suas descrições, servindo como guia para o modelo – sem solicitar retorno em JSON. Essa abordagem facilita a avaliação posterior, já que a base de dados utilizada contém documentos com informações extraídas manualmente.
Na etapa de validação, foram analisados automaticamente os campos ausentes na extração. Para verificar a coerência dos valores, um modelo avaliador foi utilizado para identificar inconsistências e fornecer justificativas quando necessário. Embora essa metodologia tenha se mostrado eficiente na maioria dos casos, foi necessária uma revisão manual das respostas. Em algumas situações, o modelo de avaliação identificava incoerências em dados que estavam corretos, mas apresentavam pequenas variações.
Foram 19 dados de comprovantes de pagamento.



A segunda fase envolveu a análise de aproximadamente 40 imagens de comprovantes de pagamento, com o objetivo de avaliar o desempenho tanto dos modelos de visão computacional quanto das soluções de OCR. Para isso, foi implementada uma pipeline em duas etapas: primeiro, a extração do texto das imagens e, em seguida, a estruturação dos dados em formato JSON.
Essa abordagem permitiu uma avaliação mais precisa do desempenho na organização das informações, utilizando um modelo específico para estruturar os dados. Isso facilitou a comparação com as extrações manuais e ajudou a identificar padrões e possíveis melhorias no processo.
Essas combinações foram selecionadas por apresentarem melhor desempenho em experimentos cruzados entre os modelos avaliados.



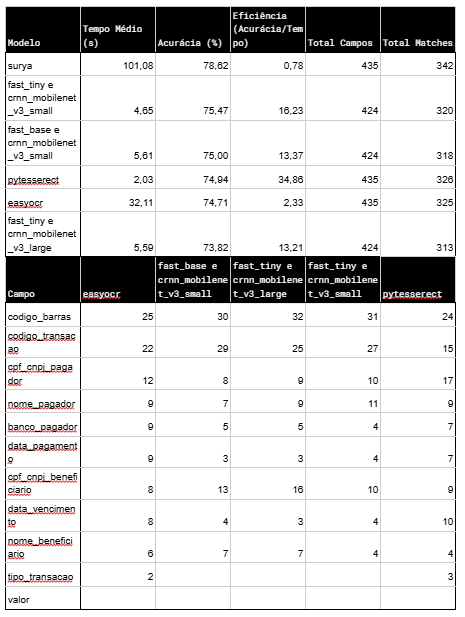


A análise comparativa entre soluções de OCR e modelos de visão computacional revelou insights importantes sobre o desempenho e as limitações de cada abordagem.
O Pytesseract destacou-se pela eficiência computacional, apresentando o menor tempo médio de processamento entre todas as soluções testadas. Já entre os modelos de visão, o Gemini-1.5-Flash-002 demonstrou o melhor desempenho geral, seguido de perto pelo GPT-4 Mini. No entanto, o GPT-4-Vision apresentou limitações na extração de determinadas imagens, possivelmente devido a filtros de conteúdo, que podem ser ajustados via prompt ou configuração dos filtros.
Um desafio comum a todas as soluções foi a extração precisa de códigos de barras, com erros recorrentes como troca de números, contagem incorreta de zeros e omissão de dígitos. Neste aspecto, o Gemini teve um desempenho superior ao GPT-4-Vision.
Além disso, a análise evidenciou que a extração direta de campos pode não ser a abordagem mais eficaz. Alguns problemas estavam mais relacionados à estruturação dos dados do que à extração em si. Isso reforça a necessidade de refinamento dos schemas para reduzir ambiguidades e melhorar a organização das informações extraídas.
Entre as versões do Gemini, o modelo 002 demonstrou maior consistência e precisão, superando o modelo 001 tanto na extração da maioria dos campos quanto na coerência geral dos resultados.
Somos uma startup inovadora com duas áreas de negócios: SaaS e AIaaS. No SaaS, oferecemos soluções avançadas para a hyperautomação de atendimento, facilitando a gestão, automação e acompanhamento de solicitações. No AIaaS, nossa plataforma Tech4.ai capacita empresas a construir e implementar soluções de inteligência artificial com tecnologias open source, garantindo agilidade, governança e alto desempenho.
E acesse, em primeira mão, nossos principais conteúdos diretamente do seu e-mail.
